Cross-Modal Fine-Tuning: Align then Refine
Junhong Shen, Liam Li, Lucio Dery, Corey Staten, Mikhail Khodak, Graham Neubig, Ameet Talwalkar
Carnegie Mellon University
Oral presentation at ICML 2023
Abstract
Fine-tuning large-scale pretrained models has led to tremendous progress in well-studied modalities such as vision and NLP. However, similar gains have not been observed in many other modalities due to a lack of relevant pretrained models. In this work, we propose ORCA, a general cross-modal fine-tuning framework that extends the applicability of a single large-scale pretrained model to diverse modalities. ORCA adapts to a target task via an align-then-refine workflow: given the target input, ORCA first learns an embedding network that aligns the embedded feature distribution with the pretraining modality. The pretrained model is then fine-tuned on the embedded data to exploit the knowledge shared across modalities. Through extensive experiments, we show that ORCA obtains state-of-the-art results on 3 benchmarks containing over 60 datasets from 12 modalities, outperforming a wide range of hand-designed, AutoML, general-purpose, and task-specific cross-modal methods. We highlight the importance of data alignment via a series of ablation studies and exemplify ORCA’s utility in data-limited regimes.
Workflow
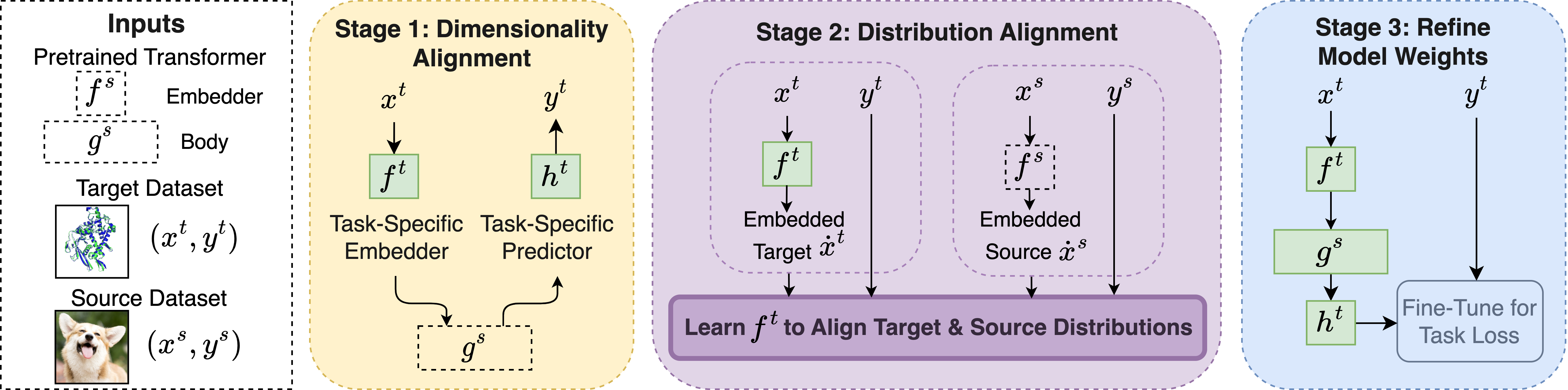
ORCA’s three-stage fine-tuning workflow enables fast and automatic exploitation of large-scale pretrained models for solving diverse tasks. In stage 1, given target data \((x^t, y^t)\) and a pretrained transformer body \(g^s\), ORCA constructs an embedder architecture \(f^t\) to map the input to the dimensionality of \(g^s\), and a predictor architecture \(h^t\) to convert the output of \(g^s\) to the target output, e.g., classification logits. The weights of \(f_t\) and \(h_t\) are randomly initialized. In stage 2, ORCA learns \(f^t\) by minimizing the distributional distance between the embedded target features and some in-modality source features. In stage 3, ORCA fine-tunes \(f^t\), \(g^s\), and \(h^t\) to minimize the task loss.
Results
Using pretrained language and vision models, ORCA obtains SOTA on 3 benchmarks—NAS-Bench-360, PDEBench, and a subset of the tabular OpenML-CC18—which contain over 60 datasets from 12 modalities. It outperforms hand-designed, AutoML, general-purpose, and task-specific methods.
On NAS-Bench-360, which includes 10 tasks with diverse input dimensions, prediction types, and modalities (vision, audio, electrocardiogram, physics, protein, genomics, and cosmic-ray), ORCA is 1st on 7/10 tasks and in the top 3 on all tasks.

On PDEBench, a benchmark of time-dependent simulation tasks, ORCA outperforms two leading baselines approaches, PINN and U-Net, and matches FNO. Here ORCA starts with a language model for 1D PDEs and a vision model for 2D PDEs.
On 16/30 OpenML tabular datasets considered by TabPFN, ORCA with a pretrained language model outperforms leading methods like XGBoost, AutoGluon, BS TabPFN. We also outperform LIFT, a task-specific cross-modal method, on 11/14 classification tasks considered in their paper.
Citation
If you find this project helpful, please consider citing our paper:
@inproceedings{shen2023orca,
author = {Shen, Junhong and Li, Liam and Dery, Lucio M. and Staten, Corey and Khodak, Mikhail and Neubig, Graham and Talwalkar, Ameet},
title = {Cross-Modal Fine-Tuning: Align then Refine},
publisher = {ICML},
year = {2023},
url = {https://arxiv.org/abs/2302.05738}
}